Les générateurs d’images d’IA ont suscité beaucoup d’intérêt ces derniers temps, mais ils peuvent être difficiles à comprendre. Voici tout ce qu’il faut savoir.
L’intelligence artificielle générative ouvre la voie à de nombreux scénarios incroyables en 2022. Après la génération de texte, la nouvelle frontière est la génération de texte dans les images et les vidéos. Dans cet article, nous allons voir comment fonctionne un générateur d’images par IA.
Le premier à avoir déclenché la grande vague a été Dall-E 2, suivi de peu par Stable Diffusion. Depuis, d’autres outils ont fait leur apparition, notamment Midjourney, Craiyon et même TikTok dans une certaine mesure. Les outils de génération d’images basés sur l’IA suscitent de plus en plus d’inquiétudes , principalement en ce qui concerne l’éthique de ces outils lorsqu’ils peuvent générer des images de personnes réelles dans des lieux ou des situations où elles ne se trouvaient pas.
Cependant, il n’y a pas que l’éthique à prendre en compte. Les générateurs d’images basés sur l’IA sont entraînés sur des millions et des millions de photos et ont appris à identifier des choses à partir de photos existantes créées par des personnes réelles. Quand cela devient-il une violation du droit d’auteur ?
Si votre IA génère accidentellement une image très similaire à un autre dessin et que le créateur de cette image la diffuse à des fins commerciales, quelqu’un est-il responsable des dommages subis ? Dans l’affirmative, qui ? Qui est l’ »artiste » dans ce cas ?
Il existe de nombreuses raisons de se méfier des générateurs d’images par IA, et ces questions d’éthique et de sécurité ne font qu’effleurer le sujet. Ces outils peuvent être utilisés pour créer de fausses images qui peuvent être utilisées pour promouvoir quelque chose de réel.
Les meilleurs générateurs d’images d’IA
Compte tenu des capacités incroyables de ces outils de génération d’images, il est effrayant de penser à ce qu’ils seront capables de faire très bientôt. Cependant, si vous voulez créer de belles images et vous amuser, il n’y a absolument rien de mal à cette utilisation. Voici les meilleurs outils disponibles.
Stable Diffusion
Stable Diffusion est la source d’inspiration de cet article et un outil avec lequel j’ai beaucoup joué ces derniers temps. Il fonctionne localement sur votre ordinateur (vous n’avez donc pas à vous battre pour les ressources avec d’autres utilisateurs d’un outil en ligne) et est l’un des plus puissants que vous puissiez utiliser à l’heure actuelle.
Il vous permet non seulement d’affiner de nombreux paramètres, mais aussi de contrôler l’ensemble du processus de génération. Stable Diffusion souffre des mêmes écueils que l’IA, avec le « danger » supplémentaire de l’accessibilité, même si vous devez disposer d’un PC suffisamment puissant pour générer des images en quelques dizaines de minutes.
La meilleure chose à propos de Stable Diffusion est qu’il est entièrement open source. Vous pouvez l’intégrer dans n’importe lequel de vos projets aujourd’hui si vous le souhaitez, et il existe déjà des plugins comme Alpaca que vous pouvez utiliser pour l’intégrer à Photoshop.
Il n’est pas encore parfait, mais il est encore très tôt dans le développement de ces programmes. Vous pouvez utiliser Dream Studio si vous le souhaitez, bien qu’il soit coûteux et un peu restrictif par rapport à la configuration locale. De plus, si vous configurez Stable Diffusion localement, il existe des forks tels que Stable Diffusion WebUI d’AUTOMATIC1111 qui sont livrés avec un outil de haut niveau intégré qui peut augmenter la résolution jusqu’à quatre fois.
Bien qu’il soit possible de générer des images à des résolutions plus élevées, il est souvent beaucoup plus rapide de générer une image à une résolution plus faible et de l’améliorer ensuite. L’entraînement à la diffusion stable a été réalisé sur un cluster de 4 000 GPU Nvidia A100 fonctionnant sur AWS et s’est déroulé sur une période d’un mois.
Il permet de générer des images de célébrités et dispose également d’un filtre NSFW intégré. Vous pouvez désactiver ce filtre NSFW sur les installations locales, car il permet d’économiser des ressources en réduisant l’utilisation de la VRAM, qui est toujours élevée.
En ce qui concerne la signification du terme « diffusion », il s’agit du processus qui commence par du bruit pur et qui s’améliore avec le temps. Il rend l’image de plus en plus proche des détails du texte jusqu’à ce qu’il n’y ait plus de bruit. C’est ainsi que fonctionne Dall-E 2.
Enfin, une autre fonction amusante de Stable Diffusion est « img2img ». Vous lui donnez une image en guise d’invite, vous décrivez ce que vous voulez que l’image soit et vous le laissez vous donner un dessin approprié, en laissant la génération complète à l’intelligence.
En résumé, Stable Diffusion est gratuit, facile à mettre en place et le plus gros problème est son accessibilité. Si vous n’avez pas un PC assez puissant, vous devrez payer pour l’utiliser via Dream Studio, ce qui n’est qu’un obstacle économique.
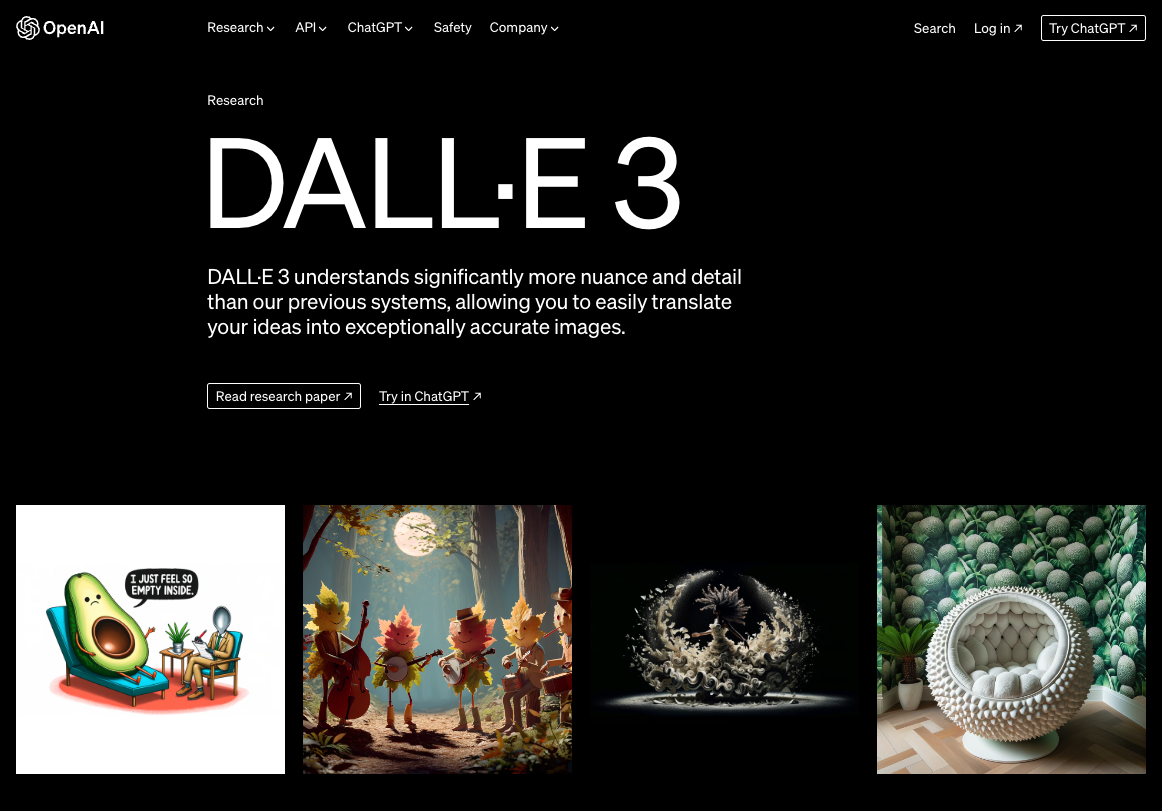
DALL-E 3
DALL-E 3 est un produit du laboratoire de recherche OpenAI et est le générateur d’images d’IA le plus connu. Son prédécesseur était autrefois fermé avec un accès restreint, mais il est aujourd’hui accessible via Microsoft Copilot et ChatGPT Plus.
Pour ceux qui peuvent y accéder, certains des résultats obtenus sont incroyables. Il a d’abord été fermé en raison de préoccupations concernant l’éthique et la sécurité d’un tel outil, mais il s’est progressivement développé au fil du temps.
L’un des principaux avantages de DALL-E 3 est sa capacité à créer des images photoréalistes qui, à première vue, ne se distinguent pas de photographies réelles et qui peuvent intégrer du texte, ce qui a toujours été difficile pour les modèles.
Il peut générer des peintures, des images qui semblent avoir été capturées par de vraies caméras et des scénarios entièrement inventés. Lorsqu’il a été annoncé pour la première fois, il a représenté un énorme bond en avant dans les capacités d’intelligence artificielle, à la fois dans sa capacité à créer des images et dans le traitement du langage naturel, connu sous le nom de NLP.
Cela est dû à la mise en œuvre de GPT-4, l’un des modèles de langage les plus avancés disponibles, également créé par OpenAI. Tout comme Stable Diffusion, DALL-E 3 a également la capacité de prendre des photos existantes et de les modifier à partir d’une invite.
Vous pouvez modifier des photos en lui demandant d’ajouter quelque chose à une image, ou même de supprimer quelque chose ou de changer l’éclairage. DALL-E 3 peut être essayé par tout le monde, soit via la version gratuite de Microsoft Copilot, soit via un abonnement payant à ChatGPT Plus.
Midjourney
Midjourney est intéressant en ce sens qu’il s’agit d’une plateforme publique qui peut générer des images, même si vous le faites par l’intermédiaire d’un serveur Discord. Bien qu’elle ait été gratuite par le passé, en raison de l’utilisation abusive de la plateforme, même le niveau d’utilisation le plus bas est désormais payant, à partir de 10 $ par mois.
C’est une barrière assez élevée quand il existe d’autres options gratuites, comme Stable Diffusion pour une utilisation locale ou l’utilisation de Microsoft Copilot. Pour vous donner une idée de la puissance de Midjourney, un utilisateur du service, Jason Allen, a créé une pièce qu’il a baptisée « Théâtre d’opéra spatial ». Il l’a présentée au concours artistique de la Colorado State Fair… et l’a gagnée.
Contrairement à ces autres projets, Midjourney est un programme d’intelligence artificielle propriétaire. Il n’y a pas de code source que vous puissiez consulter et son objectif est actuellement limité à une utilisation au sein d’un serveur Discord.
Cependant, depuis lors, l’entreprise a travaillé à la mise à jour et à l’amélioration de Midjourney. La version 6 du modèle Midjourney est la dernière version du modèle, qui est basée sur les modèles Midjourney mis en place pour s’éloigner de l’apparence » par défaut « . Aujourd’hui, Midjourney est bien meilleur qu’à l’époque, mais il en va de même pour tous ces modèles.
Craiyon
Craiyon était auparavant connu sous le nom de DALL-E Mini, bien que, malgré son nom, il n’ait aucun rapport avec DALL-E 2. Il a été créé pour reproduire les résultats du modèle d’image-texte DALL-E d’OpenAI.
Craiyon est accessible au public et peut être utilisé pour générer des images étonnamment décentes, bien que les images ne soient pas aussi précises, ni de haute qualité. La résolution des images ne dépasse pas 256×256 et il n’y a pas non plus d’outils de mise à l’échelle.
Craiyon est entièrement gratuit et accessible via son site web. Vous pouvez générer n’importe quelle image via n’importe quelle invite. Le seul problème est que les images sont de moins bonne qualité et que vous devrez attendre environ deux minutes pour chaque lot d’images générées.
Craiyon a commencé comme un modèle open source visant à reproduire les résultats du modèle DALL-E initial. Le modèle actuellement utilisé est connu sous le nom de DALL-E Mega et comporte de nombreuses améliorations, mais il n’est pas encore officiellement disponible.
Craiyon, contrairement aux autres options, est soutenu par des revenus publicitaires. Par conséquent, vous verrez des parrainages payants et d’autres publicités sur leur site web au cours de votre visite. Il existe également une application pour les smartphones Android. Elle n’est pas la plus sophistiquée, mais elle est amusante, facile à utiliser et accessible.
Les dangers et l’éthique de l’art généré par l’IA
L’art généré par l’intelligence artificielle, bien qu’intéressant, impose un certain nombre de dangers à la société dans son ensemble. À une époque où il peut être difficile de savoir si une nouvelle est prise hors contexte ou simplement inventée, il y a un danger lorsqu’il est possible de créer des images qui semblent réelles en quelques minutes.
Même si l’image générée est fausse, elle semble pouvoir être réelle et diffusée de manière illégale. Les artefacts peuvent être très bien expliqués, dans la mesure où la fausse image peut être agrémentée d’autant de faux mots.
Là où les choses deviennent encore plus obscures, c’est que vous pouvez en fait spécifier un artiste dont vous voulez que l’algorithme s’inspire. Un artiste courant est Greg Rutkowski, qui s’est élevé contre l’utilisation de son nom dans l’art généré par l’IA.
Une recherche sur le nom de Rutkowski renvoie souvent des images générées par l’intelligence artificielle qui ressemblent à ses œuvres, mais qui ne sont pas les siennes. Pire encore, l’art généré par l’intelligence artificielle peut souvent mettre en évidence les préjugés de la race humaine.
Craiyon affiche également un avertissement au bas de sa page d’accueil dans la FAQ, indiquant que « le modèle ayant été entraîné sur des données non filtrées provenant d’Internet, il peut générer des images contenant des stéréotypes préjudiciables« .
Par conséquent, la saisie de messages tels que « cadre d’entreprise » renverra très souvent des images d’hommes blancs en costume. De la même manière, l’insertion de « teacher » en tant qu’invite renverra presque toujours des images de femmes allant en classe.
L’avenir de l’art généré par l’intelligence artificielle
Comme il semble que le secteur ne ralentisse pas et que la réglementation ne rattrape pas vraiment son retard, nous nous attendons à voir de nouveaux progrès dans ces domaines. Le fait que nous soyons passés en un an des capacités de DALL-E 2 en matière de diffusion stable à DALL-E 3, qui peut générer du texte, montre à quel point ce secteur est important et potentiellement dangereux.
Des images qui auraient pu être confiées à une équipe d’artistes peuvent aujourd’hui être générées en quelques secondes, avec un seul artiste impliqué dans le processus à des fins de correction. Une économie de main d’œuvre non négligeable.
Nous avons déjà vu comment Midjourney peut vous aider à gagner un concours d’art, par exemple, bien que l’Office américain des droits d’auteur déclare actuellement qu’il n’est même pas possible de protéger les images générées par l’intelligence artificielle.
Les images coûtent également de l’argent car elles sont générées sur des serveurs incroyablement puissants, surtout lorsqu’un grand nombre d’utilisateurs viennent générer leurs propres images. Les coûts seront extrêmement prohibitifs pour tous les nouveaux producteurs entrant sur ce marché, ce qui pourrait également décourager certaines entreprises.
Cependant, les efforts initiaux tels que la diffusion stable en tant que source ouverte sont de bon augure et les utilisateurs peuvent exécuter des modèles sur leurs propres ordinateurs. Démocratiser la génération d’images decette manière, comme cela s’est produit avec LLM et LM Studio, nivelle quelque peu le terrain de jeu.
Bien sûr, depuis lors, nous avons également assisté au lancement de Sora, le modèle texte-vidéo d’OpenAI capable de générer des vidéos de 60 secondes à partir d’un simple texte. C’est effrayant et cela a un impact beaucoup plus important que la génération d’images, et avec le lancement récent de la diffusion vidéo stable, nous serons probablement en mesure de générer des vidéos complexes et longues à l’avenir.
Par conséquent, nous attendons avec impatience l’avenir de l’imagerie par IA. Le paysage a évolué très rapidement au cours de l’année écoulée et il semble que de nouvelles avancées apparaissent chaque jour. Cependant, avec la manipulation d’images basée sur l’IA qui arrive également sur nos smartphones, beaucoup de choses pourraient se produire au cours de l’année ou des deux années à venir.